Intercepting proxies are great tools in web application security tests, but they share a big weakness in their restricted search capabilities. Burp Pro offers many options in searching HTTP requests and responses, but there are still many searches that are useful in security assessments and are not possible. Examples are:
- Searching for POST requests that do not contain a specific parameter (identifying state-changing requests that lack CSRF protection)
- Searching for HTML documents without proper DOCTYPE declaration.
- Searching for missing HTTP security response headers, as X-Frame-Options.
Often, the missing piece is the combination of multiple criteria and the missing restriction to parts of the searched objects. Another issue is the poor performance of searches. Each search causes a complete sweep of all searched objects and leads to annoying delays.
The Web Audit Search Engine (short: WASE) tries to fill the gap by providing a framework for putting HTTP request/response data into an ElasticSearch index, such that it can easily be searched efficiently with available tools as Kibana. Additionaly the ElasticSearch/Kibana stack allows the creation of visualizations and dashboards.
Components
The core of WASE is a data structure for HTTP requests and response pairs for ElasticSearch and some data
post-processing code that extracts useful information from the raw data, including HTML responses. It is implemented in
doc_HttpRequestResponse.py. The class
DocHTTPRequestResponse can be used by front-ends that fill the object fields with appropriate data and call the save()
method. The calling code must initialize a connection with an ElasticSearch instance (see the elasticsearch_dsl
documentation for details) and define an index.
DocHTTPRequestResponse.init() creates the required mappings in the ElasticSearch index.
Front-ends can be standalone programs which pull HTTP requests/responses out of data or plug-ins for programs, like intercepting proxys. First I wrote ElasticBurp, a front-end for the Burp Suite. The supplementary WASEHTMLParser library contains parsing functions that are not covered by the Burp Extender API and is the intended place for similar functions in future front-ends.
The DocHTTPRequestResponse class
The core class is leaned on the Burp Extender API. Most fields of it directly correspond to data provided by Burp API calls resulting of analysis of the processes HTTP requests and responses. Therefore, headers, parameters and cookies are stored in ElasticSearch documents and are indexed for search. Most string fields are stored as analyzed and unanalyzed (field names .raw suffix), except it makes absolutely no sense, as for the HTTP request method.
Headers, parameters and cookies are stored as nested documents. Unfortunately the popular ElasticSearch front-end Kibana offers only poor support for nested documents. Particularly, the query language primarily used in Kibana does not allow to select a nested document and restrict further search expressions to it. It is possible to enter ElasticSearch DSL Queries, which are expressed in JSON that is quite unhandy in the one-line Kibana query input field. Therefore some redundancy was added in the DocHTTPRequestResponse class to make some queries easier. The created documents contain fields like request.headernames or response.cookienames to be able to search for them with simple query expressions.
Basically I learned in this project, that it makes sense to add redundancies in ElasticSearch data models for two reasons:
- Different handling of the same data in search expressions (raw and analyzed)
- Making useful data easily accessible with simplified query expressions while preserving the original data structure for complex queries
This is a bit contradictory to the data modeling theory in classical databases, as SQL.
ElasticBurp
The Burp plug-in is currently in an early development state and configured in the source code. By default it connects to a local ElasticSearch server and feeds it only with complete request/response pairs from the proxy tool.
To make things work, you first need to set up an ElasticSearch instance. Elastic offers packages for various Linux distributions. There are further download packages and Windows is also supported by installing it as service. This seemed most convenient for me, but running it standalone is also possible. As front-end I recommend the installation of Kibana. Please note that the package repositories of Elastic often contain outdated Kibana versions which aren't compatible with the ElasticSearch packages from the same repository.
For security reasons I recommend to restrict both services to listen only on the loopback interface. Usually this can be
done by setting network.host: 127.0.0.1 in /etc/elasticsearch/elasticsearch.yml and host: "127.0.0.1" in
$KIBANA_ROOT/config/kibana.yml.
Finally, ElasticBurp.py has to be loaded in Burp as extension. It was developed and tested with Jython 2.7.0. The module tzlocal must be installed with its dependencies in this Jython environment. Additionally, the root directory of the WASE source tree has to be set as module loading folder in the Burp Extenders Python Environment options or some other folder that contains the elasticsearch and elasticsearch_dsl python module. If ElasticSearch is started, the ElasticBurp extension should load without throwing any errors.
ElasticBurp now automatically feeds ElasticSearch as described above. In addition a context menu item is available that imports marked requests and responses.
Querying ElasticSearch with Kibana
After you have fed ElasticSearch with some data from a Burp session, you can open Kibana and query it. Lets pick up the examples from the introduction and search for all POST requests that don't contain a CSRF token by issuing the following query:
request.method:POST -request.parameternames.raw:"csrftoken"
Kibana should now show all requests that are likely state-changing (because of the POST method) and vulnerable against CSRF. The query itself should be self-explanatory:
- the first expression matches on all request method for the term POST.
- The minus negates the second expression and excludes all requests that contain a parametername csrftoken.
As you possibly noticed, the second expression uses the raw field instead of request.parameternames. Using the analyzed version might cause unexpected results which are not desirable in this context. Analyzed field means, that ElasticSearch decomposes the field value into smaller parts that can be searched individually. Queries against analyzed fields can cause results where the query value matches only parts of the result field value. It's usual in ElasticSearch to offer both versions and suffix the name of the unanalyzed one with .raw. The query language is described on the Apache Lucene Query Parser Syntax page.
Ok, next one. Now lets search for HTML responses without a proper DOCTYPE definition. These are worth to hunt because they can open some opportunities for XSS vulnerabilities. The following query results in all responses that Burp identified as HTML by its own content sniffing logic that doesn't contain a DOCTYPE definition in the HTML code:
response.inferred_content_type:html -doctype
You will possibly see many redirections and like to restrict to 200 responses that likely contain some user-provided content. This query does the trick:
response.status:200 AND response.inferred_content_type:html -doctype
Take care of the AND in the expression. Omitting it causes that HTML responses and 200 responses will be contained in your results. Further interesting responses are those that were not declared as HTML, but detected as such ones by Burp:
response.inferred_content_type:html -response.content_type:html
There is a good chance that browsers also recognize HTML and there are possibilities for XSS vulnerabilities. It is useful to select fields in the left part of the Kibana UI or directly in expanded results document. Selecting fields means that they are displayed in the condensed list view instead of the first lines of the whole result document. This makes the list more clear, like in the following screenshot:

Last example: searching for responses with missing security headers. The following query finds them:
NOT response.headernames:"X-Frame-Options"
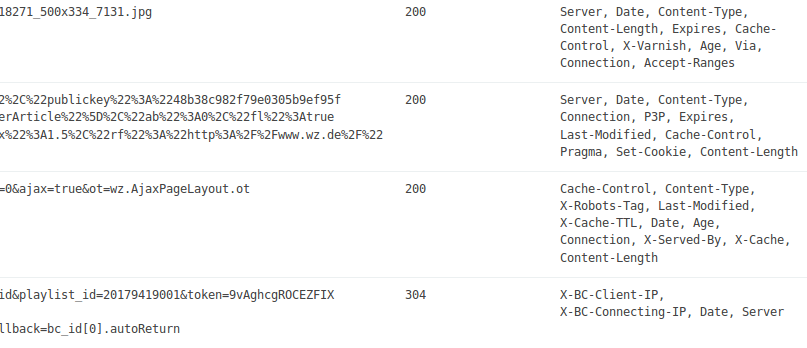
As you can see, WASE can support you in finding security issues by targeted searches for specific conditions in requests and responses.
Future Development
WASE is still in an early stage of development. In the first line, there is surely more interesting data that can be extracted as field. Possibly there are other areas outside of security where it could get a useful tool.
There are some ideas for further front-ends:
- Importing HTTP traffic from PCAP files
- Importing of Burp save (requests/responses) files
- Plugin for Zed Attack Proxy (ZAP)
I plan to submit the ElasticBurp plug-in to the BApp Store, but first it needs to be configurable via UI instead of editing the source code.
Building useful visualizations and dashboards in Kibana is also on the to-do list. Kibana offers a neat generic front-end for ElasticSearch, but has unfortunately some drawbacks. Summarized these are:
- It doesn't supports nested documents very well
- Querying of nested documents requires usage of JSON-based Query DSL syntax
- No pretty printing or compression of responses, causes much scrolling when results are expanded
- Visualizations and dashboards have shown to be too restricted in the given use case
So there is the plan to build an own web-based UI front-end.
Feel free to open bugs or enhancement requests. Pull requests are also appreciated :-)
Thanks go to Daniel Sauder for proofreading!