This article gives an introduction to EQUEL, an Elasticsearch Query Language I've released as open source Python library. As it got a bit lengthy, feel free to skip directly to the example use case section, when you're not interested in the motivation and the theory around it.
Where is the Problem?
Elasticsearch gained huge popularity in the area of forensics and log analysis (or Security Information and Event Management, SIEM). Kibana is usually the first choice and a great tool for searching and visualizing log data stored in Elasticsearch. Unfortunately, Kibana doesn't exposes the complete set of the capabilities that Elasticsearch offers under the hood. One of these capabilities I often miss while analysing logs is the top hits metric aggregation which allows to show the documents that form a bucket. Current Kibana versions expose it, but complete documents can only be displayed as JSON. Further, Kibana only offers to build linear aggregation nesting structures while Elasticsearch supports complex trees of aggregations with parts that are independent to each other. The documentation further lists many query types and aggregations that are not offered by Kibana.
Over a year ago, I discovered that Elasticsearch also fits well into some aspects of my offensive security work and started to develop a toolchain called WASE that aims to support web application security testing with advanced search capabilities of Elasticsearch. WASE heavily uses nested fields and it turned out quickly, that Kibana doesn't support them very well. Moreover, Elasticsearch Query Strings are not capable of searching inside of nested documents and to express aggregations at all.
A workaround for search restrictions is the usage of Query DSL in the Kibana query input field. Unfortunately, this JSON-based format is quite human-unfriendly due to the deep nesting that is often required to express search queries. Another solution is to build special purpose tools like WASEQuery that use the required APIs. Because I use Elasticsearch for many different things, I started to develop a more generic approach, that resulted in EQUEL.
What is EQUEL?
The main goal of EQUEL is to provide access to as many Elasticsearch features as possible with a query language that is easy to understand and write for humans. Users should write queries in a linear syntax without the requirement for many layers of nesting. Further, the user should be able to express queries and aggregations in one expression. The whole thing should be a framework that allows to add own outputs and visualizations of data and to extend the capabilities of Elastisearch with postprocessing modules. Further, it should be possible to use it as drop-in replacement in existing applications.
Disclaimer before you continue to read this section: you should be familiar with Elasticsearch queries, aggregations and other features of it. I tried to link the corresponding documentation, but the example sections below may be better to understand without a deep understanding of Elasticsearch.
Basically, an EQUEL expression consists of one or multiple subexpressions with the syntax:
verb1 param1=val1 param2=val2 param3 ...
Multiple subexpressions are connected via the pipe character. The first subexpression may be an Elasticsearch Query String. Subexpressions can be grouped in the following categories:
- search/search modifiers
- aggregation
- postprocessing
- output
A complete EQUEL expression looks as follows:
search | searchmodifier1 | ... | agg aggregation1 | aggregation2 | ... | postproc postproc1 | ... | output output1 | ...
Currently, the order of expressions from the above categories is strict and the first expression of a category must be prepended with the corresponding keyword. This is something I want to simplify in the future, but for the first it makes parsing and disambiguation a bit easier.
EQUEL expressions start with a query, which is usually an Elasticsearch Query String (the expressions you usually
type into the Kibana search bar), but may be also something else from the Query DSL, like script queries. Search
modifiers are sorting orders or field selection, stuff from this area of the Elasticsearch
documentation. This is
followed by an arbitrary number of
aggregations, initiated
by the keyword agg at the beginning of the subexpression. Aggregation can be named with an as name at the end
of the subexpression:
agg aggregation param=val ... as foobar
The names can then be used in combination with the agg keyword to build aggregation trees:
agg foobar aggregation ...
This will cause that the following aggregation is nested below the foobar aggregation from above.
The categories postprocessing and output have a similar syntax. Outputs can also be named for selection of displayed outputs. Postprocessing is not yet implemented, but my next development efforts will concentrate on this category.
Currently, EQUEL can be used from a command-line client equel-cli.py that is contained in its source tree.
A remarkable fact is that EQUEL already has its own logo:

Installation
Install the dependencies listed in the README file under the requirements section. Please be aware that EQUEL is developed with Python 3.
Usage Example: Linux Logs
The example is based on Elasticsearch authentication indices created with the logstash-linux configuration. Lets begin with a simple example and extract failed SSH logins, as we would search for them in Kibana:
./equel-cli.py --index 'logstash-auth-*' 'program:sshd AND ssh_authresult:fail'
This will result in:
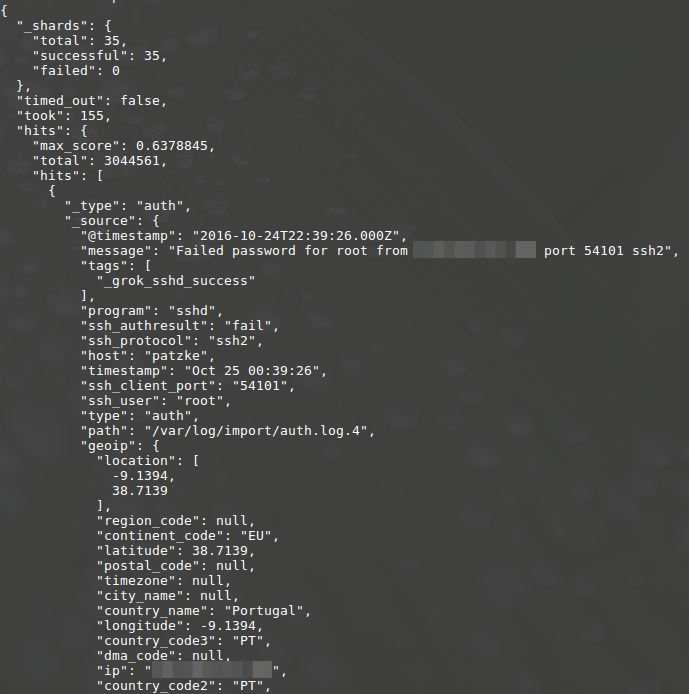
By default EQUEL simply returns the JSON output of Elasticsearch, but it offers other output options:
./equel-cli.py --index 'logstash-auth-*' 'program:sshd AND ssh_authresult:fail | output text'
Results in:
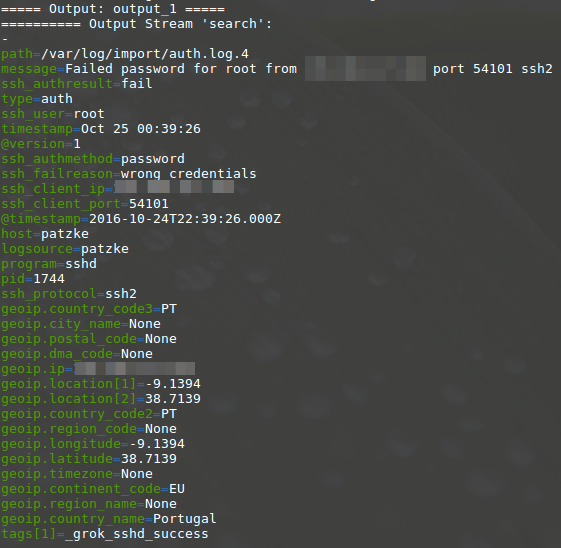
This is much better to read, isn't it? The output module text was added. Generally, one EQUEL expression can contain an arbitrary number of outputs and each output can generate as many output streams as needed. Output can be further optimized with options:
./equel-cli.py --index 'logstash-auth-*' \
'program:sshd AND ssh_authresult:fail
| output text mainfield=message fields=[timestamp,ssh_client_ip,ssh_user,geoip.country_name] condensed'
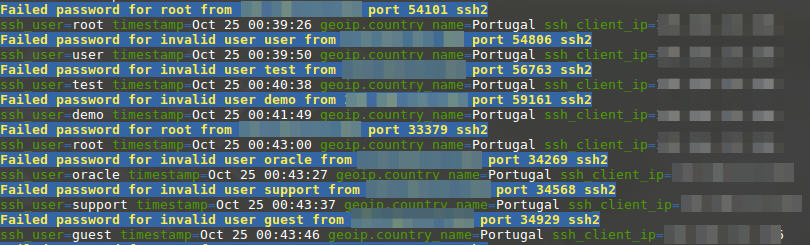
Now the field message is used as title for a hit, only interesting fields are displayed and the output is condensed into one line.
You're missing CSV output of search results in Kibana? EQUEL can do it:
./equel-cli.py --index 'logstash-auth-*' \
'program:sshd AND ssh_authresult:fail
| output csv fields=[timestamp,ssh_client_ip,ssh_user,geoip.country_name]'
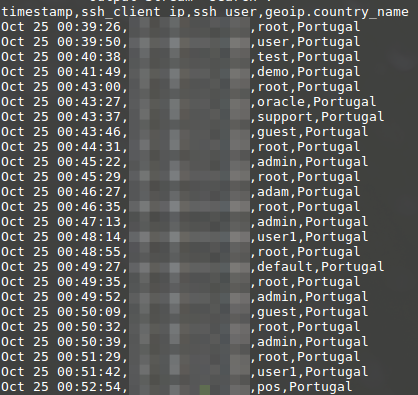
Instead of text, the CSV output module is now used with a list of fields that should be contained in it. This output can be used in the Spreadsheet program of your choice.
Now lets try to discover a common attack pattern by aggregating the failed login events by authentication sources that try to login with many user accounts:
./equel-cli.py --index 'logstash-auth-*' --output out.aggregations \
'program:sshd AND ssh_authresult:fail
| agg terms field=ssh_client_ip.keyword order=usercount.value- as source
| terms field=ssh_user.keyword as user
| agg source cardinality field=ssh_user.keyword as usercount
| output text as out'
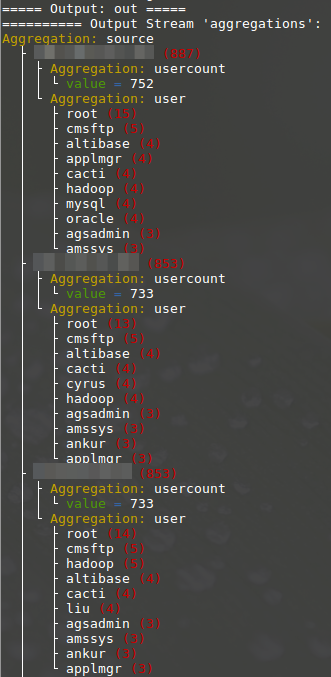
This EQUEL expression accomplishes the following:
- It searches for all failed SSH logins.
- The failed logins are aggregated into a bucket per source IP. This aggregation is named source.
- The source buckets are further aggregated into buckets per attempted user account. This one is named user.
- A metric aggregation child usercount is added to source that counts the number of user names attempted in failed logins.
- The source aggregation buckets are ordered descending by the usercount metric.
- The result is rendered by the text output module.
- As we are only interested in the aggregation result, this output stream is selected with the
--outputparameter.
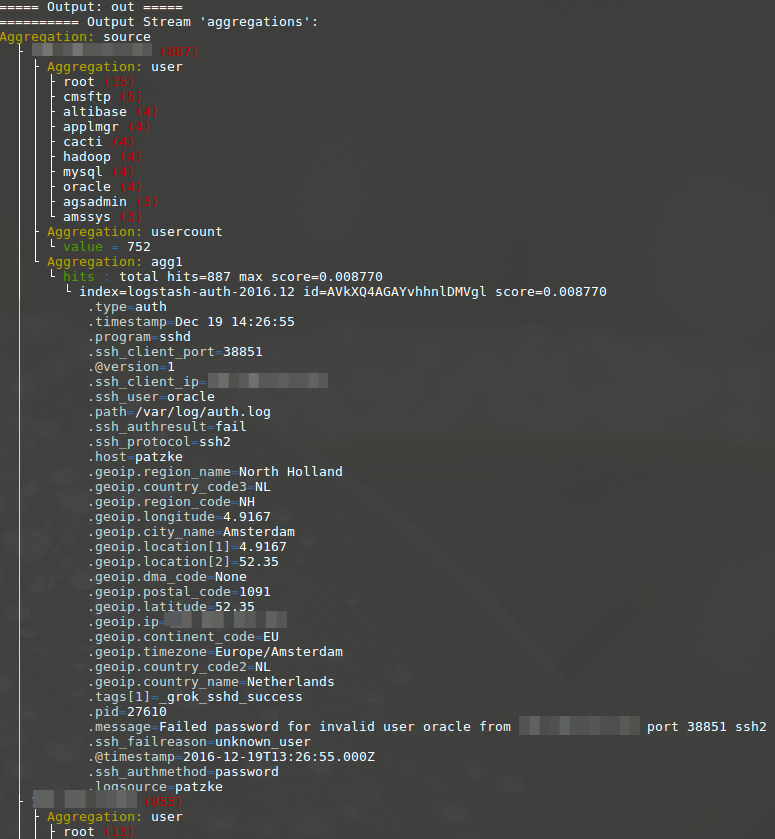
Finally, lets add one log record per source with the top_hits aggregation:
./equel-cli.py --index 'logstash-auth-*' --output out.aggregations \
'program:sshd AND ssh_authresult:fail
| agg terms field=ssh_client_ip.keyword order=usercount.value- as source
| terms field=ssh_user.keyword as user
| agg source cardinality field=ssh_user.keyword as usercount
| agg source top_hits size=1
| output text as out'
By the way, often used aggregations like terms have shortcuts in EQUEL, currently without the support for parameters. The above EQUEL expression can be shortened a bit as follows:
./equel-cli.py --index 'logstash-auth-*' --output out.aggregations \
'program:sshd AND ssh_authresult:fail
| agg terms field=ssh_client_ip.keyword order=usercount.value- as source
| :ssh_user.keyword
| agg ~ssh_user.keyword as usercount
| agg source top_hits size=1
| output text as out'
The cardinality aggregation was replaced with the shortcut '~', terms with ':'. Further, the name of user was omitted, as it is not required.
I will publish a blog post that describes the usage of EQUEL with the WASE framework and how nested documents can be searched.
Integration in Own Projects
There are different ways to integrate EQUEL into an existing software project. Generally, the main class is
equel.engine.EQUELEngine. It can be instantiated with the server name (by default localhost), an index pattern
(*) and a timeout value as parameter. An EQUEL expression is then parsed with the instance method
.parseEQUEL(equel) or a file with .parseEQUELFile(filename). This returns an EQUELRequest object instance
that can be converted into Elasticsearch DSL with .jsonQuery(). .execute() performs the request against the
server and index defined in the EQUELEngine object. Obviously, usage of .jsonQuery() only supports queries and
aggregations.
The method .execute() returns an EQUELResult object (or throws an exception in case of an error), which
contains EQUELOutput instances in the .outputs property. An EQUELOutput object behaves like a dictionary and
contains all generated output streams. An output has a type (text, HTML or image) that can be used by further
output processing to handle the output properly.
See the source code of equel-cli.py as reference.
Future Plans
EQUEL is currently in an early development stage. As the query language is rather static in many areas and contains some cruft in its syntax, much improvement is required in this area. Therefore, it shouldn't be expected that the query language will be stable. Further, internal APIs may change and therefore the way how plugins are implemented.
My development efforts in the near future will concentrate on threat hunting use cases, mainly:
- Implementation of a join-like operation as post-processing module. Example: mapping Windows Event IDs or failure codes to descriptive text.
- A post-processing module for temporal correlation of events. Idea: search the temporal context of each search hit for hits to another query. Include additional hits of such searches or drop original hit if secondary search fails to find anything. Example: loading of related executables or libraries like in this Sigma rule.
- Graphviz/vis.js/Neo4j outputs for aggregations. Example: creation of network flow diagrams, process dependency graphs etc.
Further improvements could be:
- Cleanup of the syntax
- Check if all Elasticsearch features behave as expected and create appropriate classes to make them accessible. Scripted fields in aggregation are one example of something that may not work currently.
- Development of a rudimentary web GUI.
- Development of a proxy that translates transparently between EQUEL and Elasticsearch queries.
As I'm expecting a shortage of time in the next months, feel free to pick up one of these ideas or bugs you discover and contribute with pull requests :)
Credits
Big thanks go to Florian Roth for much valuable input and the fancy logo. Without Ralf Glauberman, the name of EQUEL would be possibly EESQL or something that sounds less nice today.