In my previous blog article I gave an introduction into EQUEL, an Elasticsearch query language that exposes ES functionality beyond the capabilities offered by Kibana and many other tools. This article describes the usage of EQUEL in combination with WASE, the Web Audit Search Engine, a tool that feeds an Elasticsearch instance with HTTP request/response data from the Burp Suite or from the included proxy server. WASE uses nested documents to for storage of HTTP parameter values, header data and cookies. Unfortunately, nested documents are not well supported by Kibana and Elasticsearch query strings. This blog post describes briefly the crawling of URLs with curl and WASEProxy. After some test data is acquired, I describe how nested documents can be searched and aggregated with EQUEL.
Collecting Test Data with WASE
In this example, Cisco Umbrella Top 1m list of domains is used as base for crawling. The list can be downloaded here. Unpack the zip and generate a list of URLs with:
cut -f2 -d, top-1m.csv | head -1000 | perl -ne 'chomp; print "http://$_\nhttps://$_\n"' > urls.txt
This command line selects the first 1000 domain names and generates HTTP and HTTPS URLs from it.
The installation of WASE with its dependencies in a Python virtualenv can be accomplished with:
git clone https://github.com/thomaspatzke/WASE.git
cd WASE
virtualenv pyenv
. pyenv/bin/activate
pip install -r requirements-proxy.txt
./WASEProxy.py
The last line invokes WASEProxy in its default config on Port 8080 that uses an Elasticsearch on localhost and puts new data into the index wase-proxy.
Crawling with curl should be parallelized with GNU Parallel, which must be installed before continuing here. Curl must also be installed. Finally, the following command line starts the crawling of the URLs extracted previously:
cat urls.txt | parallel --progress -j10 --joblog wase-scan.joblog curl -L -k -x localhost:8080 -o /dev/null -s -m 10
This command line parallelizes by invocation of 10 parallel curl instances and stores the progress in a joblog
file. This is useful for later resumption of larger scans. GNU Parallel invokes curl instances that use WASEProxy
(-x), follows redirection (-L), never checks certificates (-k), doesn't generates output (-o), timeouts
after 10 seconds (-m) and is silent (-s).
After this has finished, the Elasticsearch instance is filled with the crawl data.
Nested Queries
The inital WASE blog post already describes some useful queries. A further one describes enhanced requests with a specialized tool, WASEQuery. Lets search all Content Security Policies that contain the word unsafe:
./equel-cli.py --index wase-proxy \
'response.headers.name:Content-Security-Policy AND response.headers.value:unsafe
| nest path=response.headers
| output text mainfield=request.url fields=[response.headers.name,response.headers.value] maxvallen=10000'
The first part of this EQUEL expression is a valid query string, but will fail in Kibana:
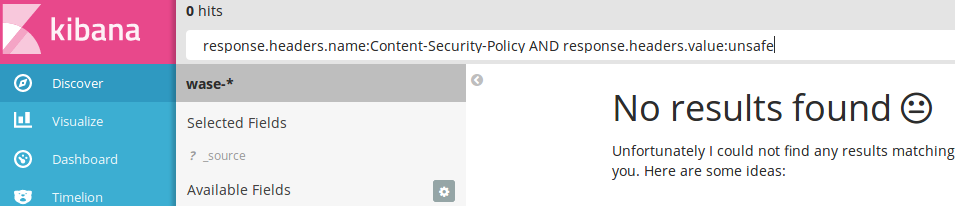
The reason for this behaviour is caused by the internal structure of the WASE data stored in Elasticsearch. The field response.headers contains a nested document with the field name and value with corresponding header data. The second part of the expression (nest) wraps the previous query into a nested query. This causes that the query string search is now able to find the searched data inside of the nested document. The last part of the EQUEL expression beautifies the output a bit:
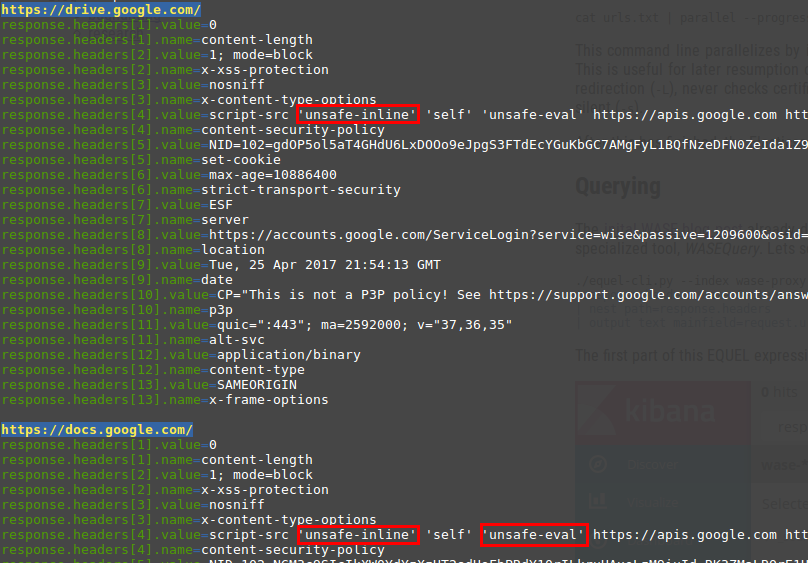
Seems that Google uses unsafe-* directives, although they discourage its usage somewhere
else ;-)
Still want to use Kibana? It's possible to enter Elasticsearch DSL JSON queries directly into the search bar, but you don't want to type these expressions yourself, EQUEL generates them for you:
./equel-cli.py --compileonly \
'response.headers.name:Content-Security-Policy AND response.headers.value:unsafe
| nest path=response.headers'
Generates this output:
{
"query": {
"nested": {
"path": "response.headers",
"query": {
"query_string": {
"query": "response.headers.name:Content-Security-Policy AND response.headers.value:unsafe"
}
}
}
}
}
Copy and paste everything below query in Kibana and you get the search result:
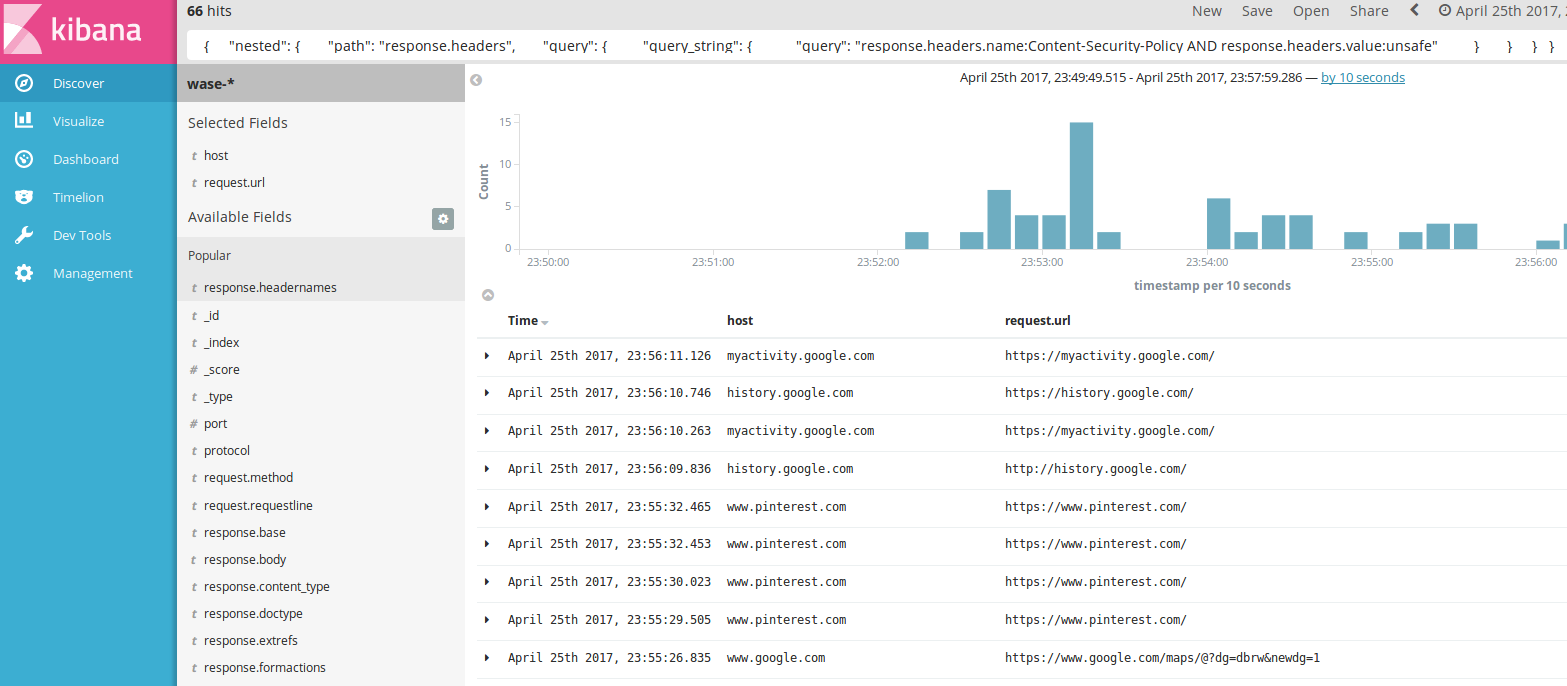
Aggregations
The above output is maybe a bit too detailed. If you scan the net or your organization for weak Content Security Policies or other stuff, lets make a breakdown by hosts and URLs by using aggregations:
./equel-cli.py --index wase-proxy --outputs output_1.aggregations \
'response.headers.name:Content-Security-Policy AND response.headers.value:unsafe
| nest path=response.headers
| agg :host
| :request.url.keyword
| output text'
This example just uses simple terms aggregations which are expressed with their EQUEL aggregation shortcut. The query results in a list of top 10 domain names with top 10 URLs with possibly weak content security policies that contain the word unsafe:
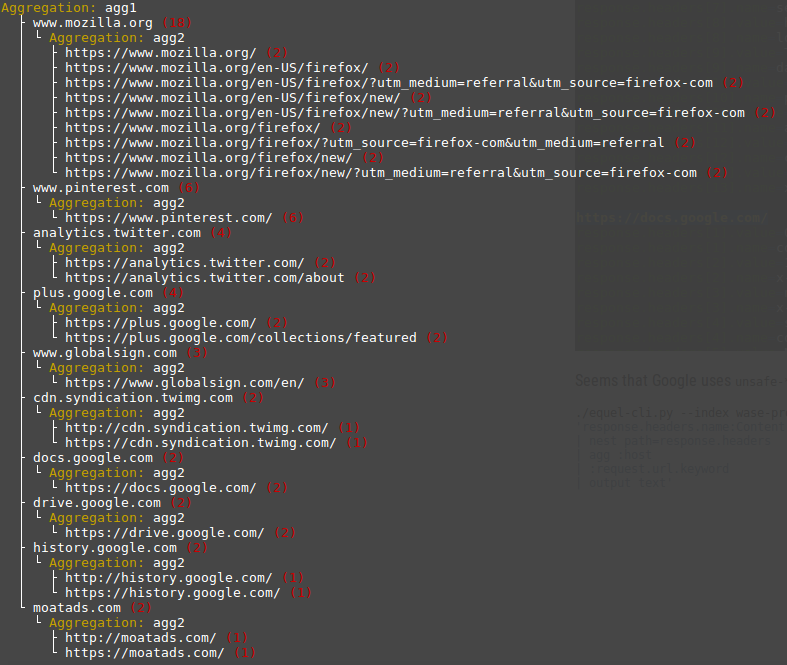
Nested Aggregations
Now lets do a really complex aggregation and build an overview of most popular values of HTTP security headers. Such an aggregation must traverse into nested documents, as the data that should be aggregated is located there. This command line generates it:
./equel-cli.py --index wase-proxy --output output_1.aggregations \
'*
| agg nested path=response.headers as secheaders
| filter query="response.headers.name:x-frame-options" as xfo
| :response.headers.value.keyword as xfovals
| agg secheaders filter query="response.headers.name:x-content-type-options" as xcto
| :response.headers.value.keyword as xctovals
| agg secheaders filter query="response.headers.name:strict-transport-security" as sts
| :response.headers.value.keyword as stsvals
| agg secheaders filter query="response.headers.name:x-xss-protection" as xxp
| :response.headers.value.keyword as xxpvals
| output text'
Looks complicated? It's easier than it appears!
The first line of the EQUEL expression searches all documents. The nested aggregation in the next line causes, that all aggregations below this work on the nested documents given by the path parameter. Remind here that Elasticsearch aggregations are structured in a hierarchical tree. In the next line, the filter aggregation filters the nested response header documents for X-Frame-Options headers. Finally, the terms aggregation from the next line aggregates the values from the filtered documents.
From here, the filter and terms aggregation is repeated for each analyzed header. The prefix agg secheaders
causes that the aggregation is not located below the previous terms location (the result would be empty, because
both filters operate on completely disjunct document sets), but below the initial nested aggregation. All
aggregations are named here with the as keyword for better readability of the result. Only the first aggregation
must have its name, as it is referred in later aggregation definitions.
Enough said, here's the result:
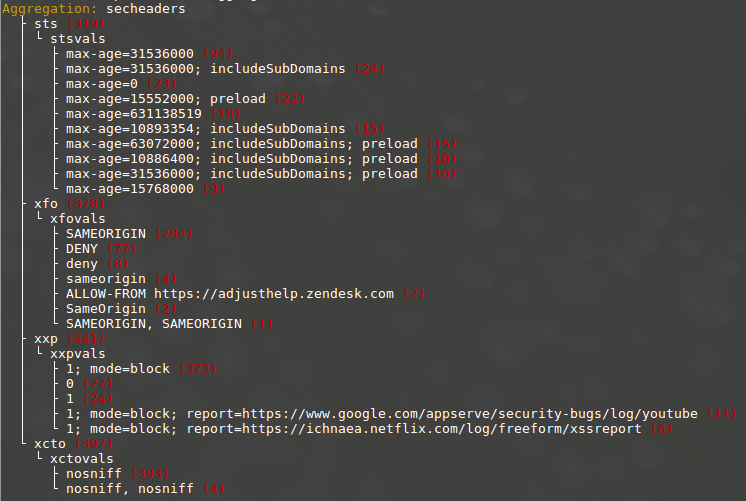
And this is the Elasticsearch JSON query that is generated by EQUEL:
{
"aggs": {
"secheaders": {
"aggs": {
"xcto": {
"aggs": {
"xctovals": {
"terms": {
"field": "response.headers.value.keyword"
}
}
},
"filter": {
"query_string": {
"query": "response.headers.name:x-content-type-options"
}
}
},
"xfo": {
"aggs": {
"xfovals": {
"terms": {
"field": "response.headers.value.keyword"
}
}
},
"filter": {
"query_string": {
"query": "response.headers.name:x-frame-options"
}
}
},
"xxp": {
"aggs": {
"xxpvals": {
"terms": {
"field": "response.headers.value.keyword"
}
}
},
"filter": {
"query_string": {
"query": "response.headers.name:x-xss-protection"
}
}
},
"sts": {
"aggs": {
"stsvals": {
"terms": {
"field": "response.headers.value.keyword"
}
}
},
"filter": {
"query_string": {
"query": "response.headers.name:strict-transport-security"
}
}
}
},
"nested": {
"path": "response.headers"
}
}
},
"query": {
"query_string": {
"query": "*"
}
}
}
Appears to be more complicated than the EQUEL expression.